Method Overview
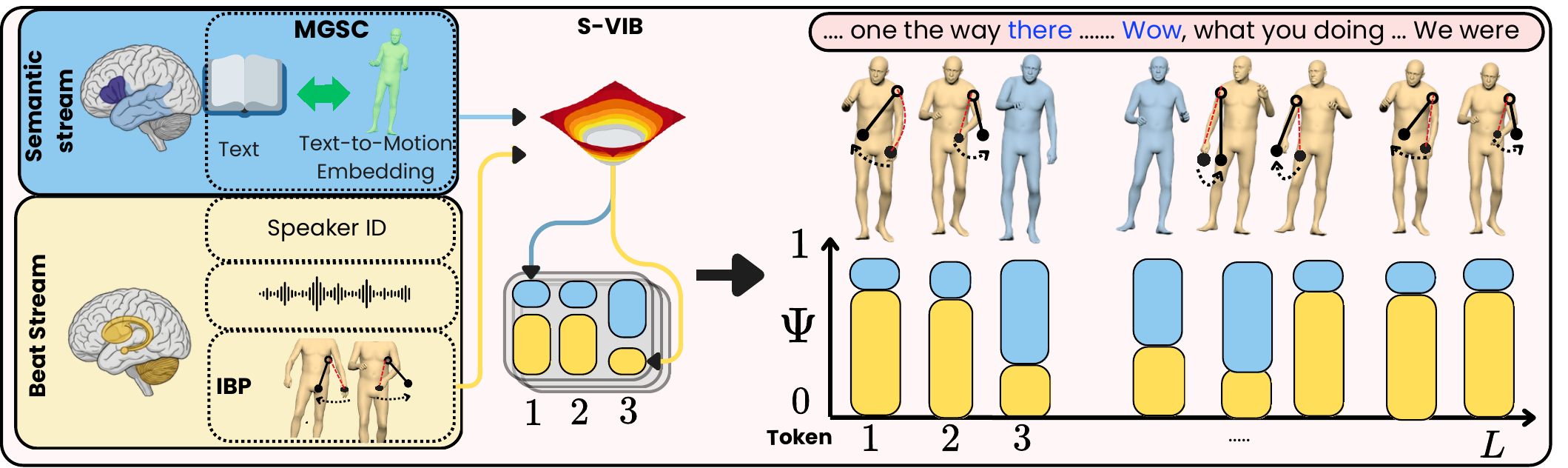
DuoGesture models co-speech gesture generation as the interaction of two coupled processes: a semantic stream for sparse lexical gestures and a beat stream for rhythmic prosody-aligned motion.
Highlights
DuoGesture addresses the tension between semantic expressivity and biomechanical plausibility in holistic co-speech gesture generation.
Dual-Stream Gesture Generation
Co-speech motion is decomposed into a semantic stream and a beat stream, reflecting the distinction between sparse lexical gestures and frequent rhythm-aligned beat gestures.
Motion-Grounded Semantic Conditioning
MGSC replaces purely linguistic embeddings with text-to-motion representations, providing motion-aligned semantic priors for long-tailed gesture triggers.
Semantic Variational Information Bottleneck
S-VIB introduces a stochastic frame-level gate that learns when semantic motion should override beat motion while avoiding deterministic gate collapse.
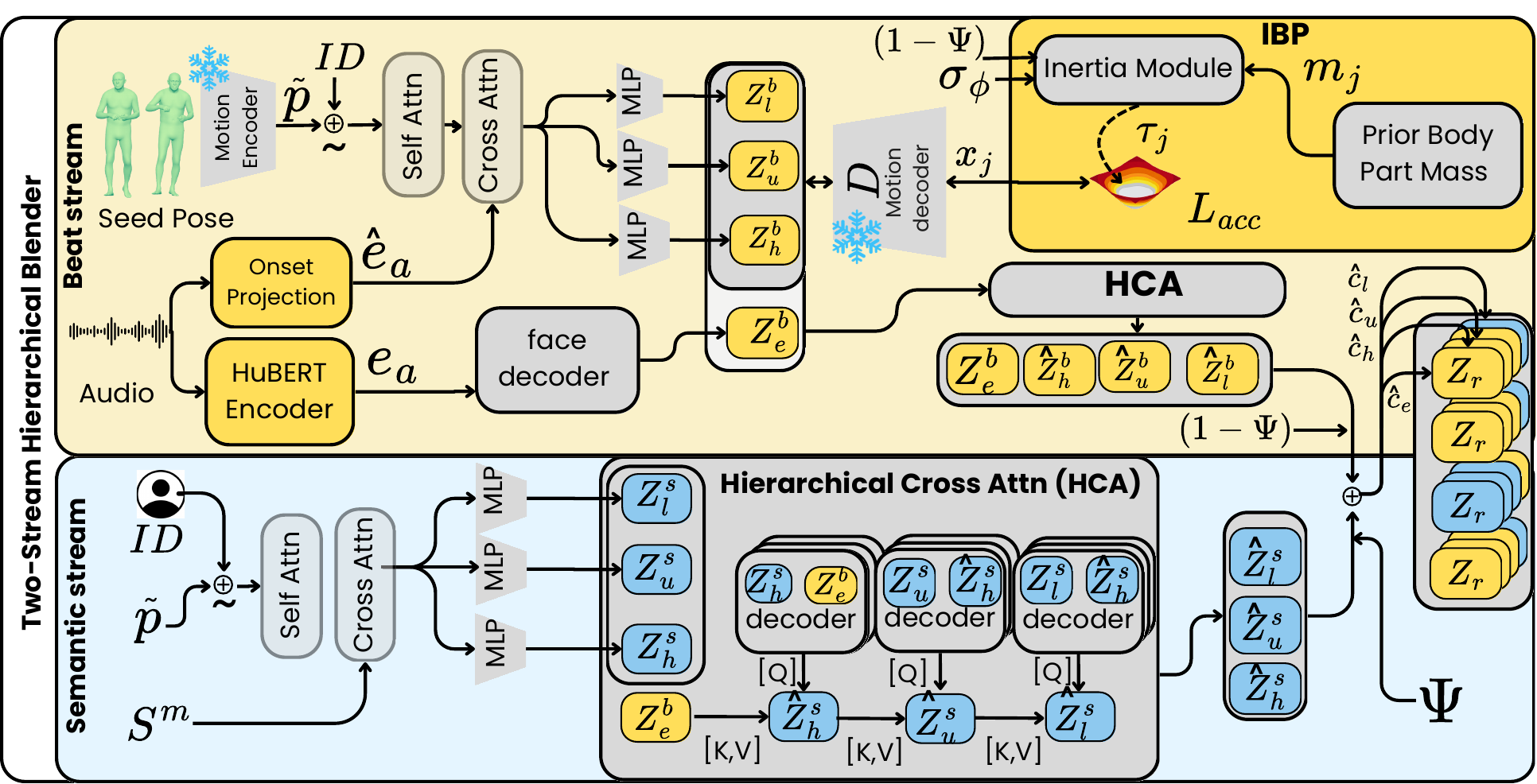
Inertial Beat Prior
IBP applies an anthropometric arm-chain prior to reduce jitter and improve rhythmic consistency without constraining expressive semantic frames.
Abstract
Co-speech gesture generation requires both semantic expressivity and biomechan- ically plausible rhythmic motion. Existing holistic gesture models mix lexically grounded semantic gestures with frequent prosody-aligned beat gestures. This lim- its semantic grounding, speech-motion alignment, and kinematic smoothness. We propose DuoGesture, a neuro-inspired and biomechanically informed dual-stream approach that decomposes co-speech gesture synthesis into coupled semantic and beat streams. The two streams are coordinated by a Semantic Variational Information Bottleneck, a stochastic frame-level gate that learns when semantic gestures should override rhythmic beat motion. The semantic stream is controlled by Motion-Grounded Semantic Conditioning, which replaces purely linguistic word embeddings with motion-language representations to provide motion-aligned semantic priors for long-tailed lexical triggers of gestures. The beat stream is fur- ther regularised by an Inertial Beat Prior, an anthropometry-weighted arm-chain module that reduces jitter and improves rhythmic consistency without constraining semantic frames. Objective evaluations and subjective experiments show that Duo- Gesture outperforms strong holistic baselines, while component ablations confirm the complementary roles of semantic grounding, stochastic stream selection, and biomechanical regularisation.
Framework Overview
DuoGesture is a two-stage latent generator. Stage 1 uses a regional RVQ-VAE tokenizer. Stage 2 predicts latent gesture codes through a convex combination of semantic and beat branches controlled by a stochastic frame-level gate.
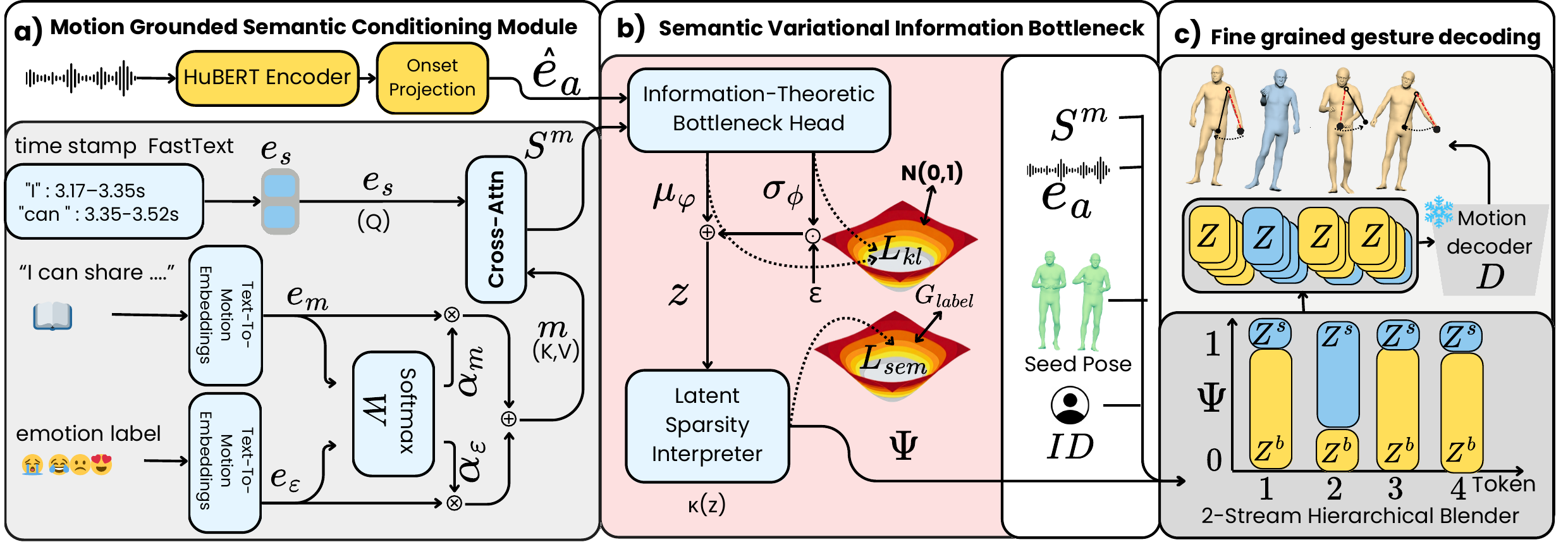
Motion-Grounded Semantic Conditioning
Instead of relying on BERT or FastText embeddings, MGSC uses a text-to-motion latent space to provide semantic features that are already aligned with gesture morphology.
Stochastic Semantic Gate
A variational bottleneck predicts frame-level semantic weights, encouraging temporal sparsity and preventing the gate from collapsing into a deterministic all-semantic state.
Biomechanical Beat Prior
An anthropometric arm-chain smoother injects inertial structure into the beat branch, reducing jerk while avoiding penalties on expressive semantic frames.
Why Two Streams? ‐ Motivation for the IBP
Beat and semantic arm-swings have fundamentally different spectral signatures ‐ and that difference is what makes the Inertial Beat Prior both possible and necessary.
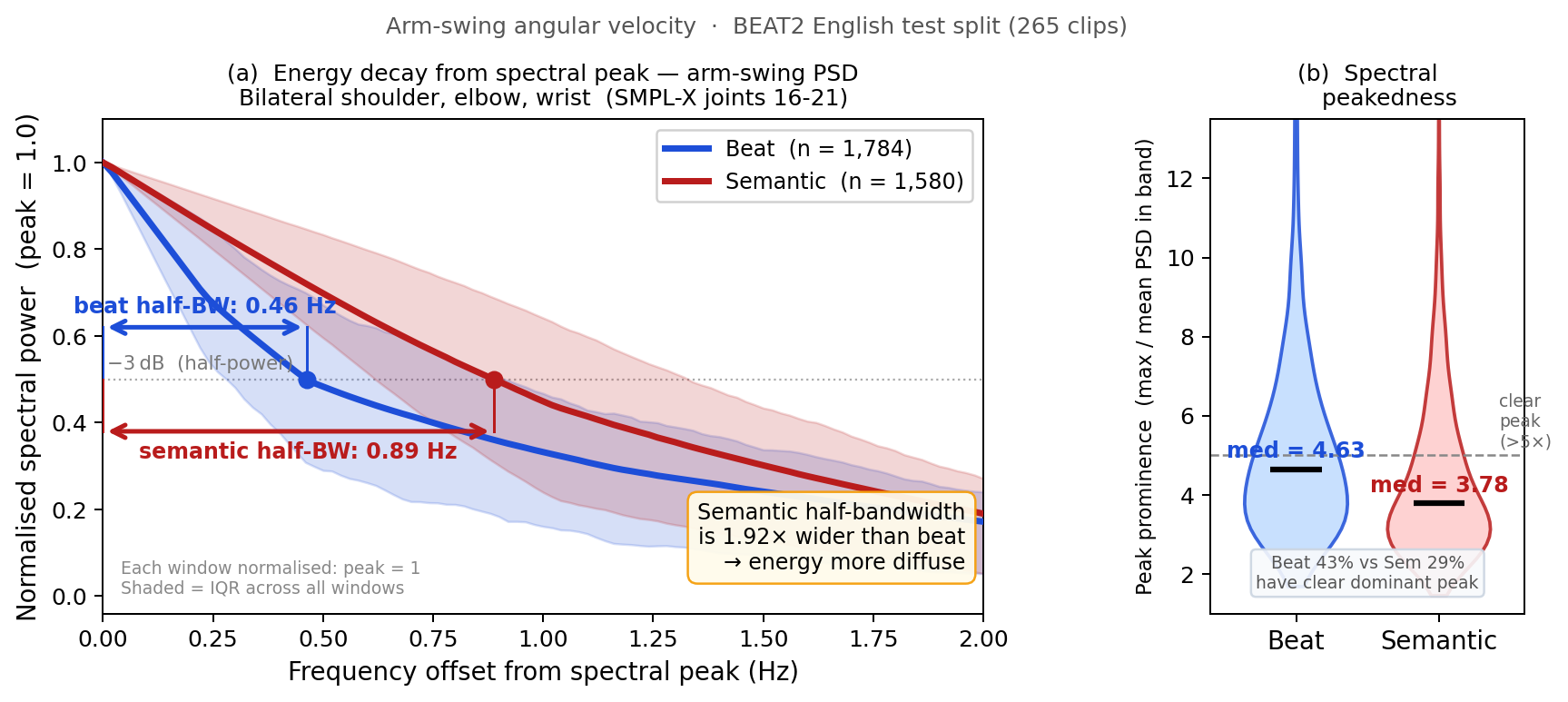
Rhythmic & periodic ‐ like a metronome
Beat arm-swings repeat at a steady pace in sync with speech prosody. Their energy spikes at one tight frequency (half-bandwidth only 0.46 Hz), just like a pendulum. 43% of beat windows show a single unmistakable dominant peak.
Expressive & varied ‐ like a dance move
Semantic gestures vary freely in speed and timing to express meaning. Their energy spreads nearly twice as wide (0.89 Hz) and only 29% have a clear spectral peak ‐ they don’t follow a single rhythm.
Apply physics only where motion is already physical
Because beat arm-swings are naturally periodic, we enforce a lightweight anthropometric arm-chain constraint on the beat stream alone ‐ smoothing jitter exactly the way real arm inertia would, without ever penalising the free-form expressive frames of the semantic stream.
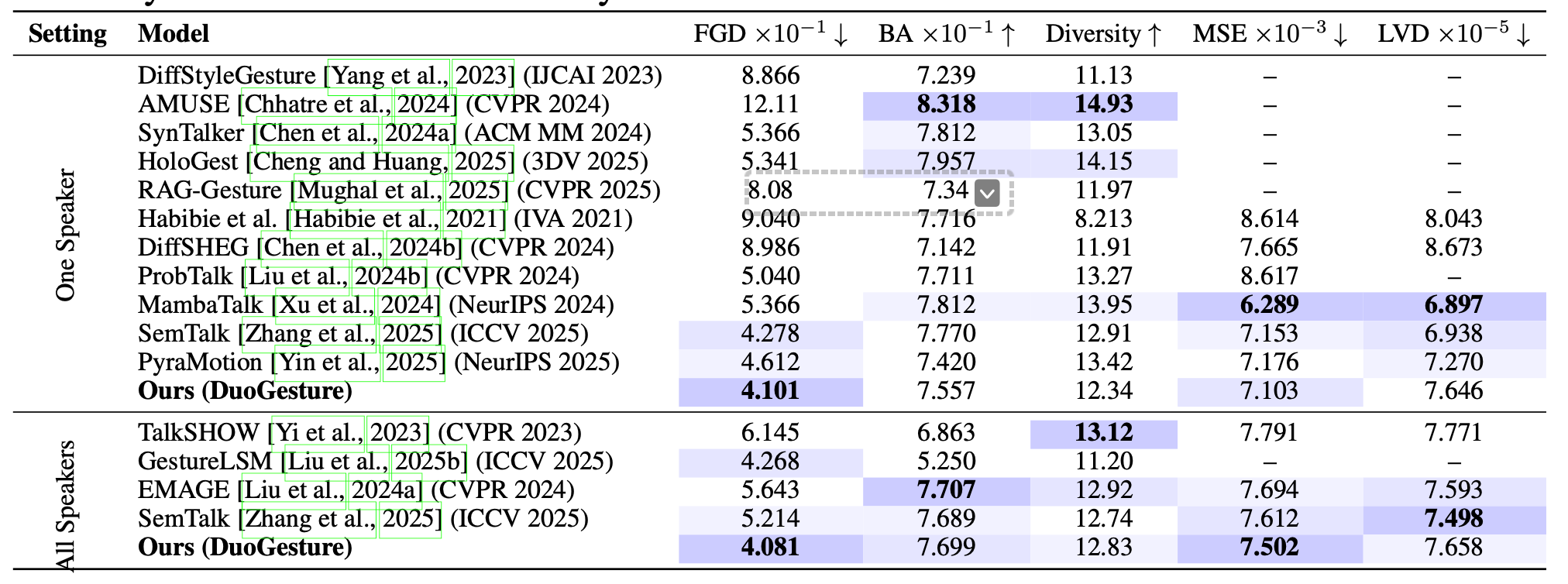
Quantitative Results
On BEAT2, DuoGesture improves distributional fidelity over strong holistic baselines in both one-speaker and all-speaker settings, while maintaining competitive beat alignment and motion diversity.
Component Ablation
Component-wise ablations show that MGSC drives most of the FGD gain, S-VIB improves diversity and prevents gate collapse, and IBP preserves beat consistency with minimal trade-off.

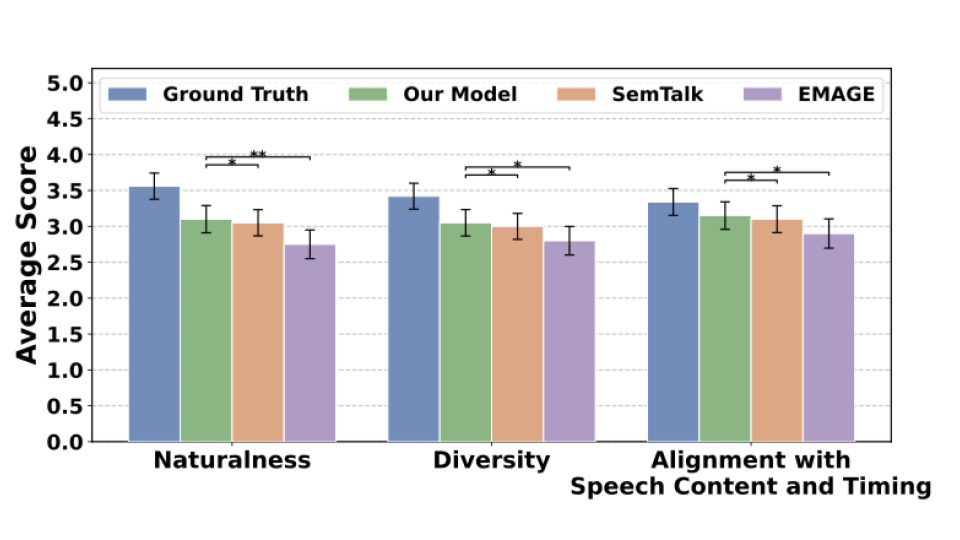
User Study
A controlled user study was conducted using 35-second clips from the BEAT2 test set across six narrated topics. Thirty native English speakers evaluated randomly ordered sequences on naturalness, diversity, and alignment with speech content and timing.
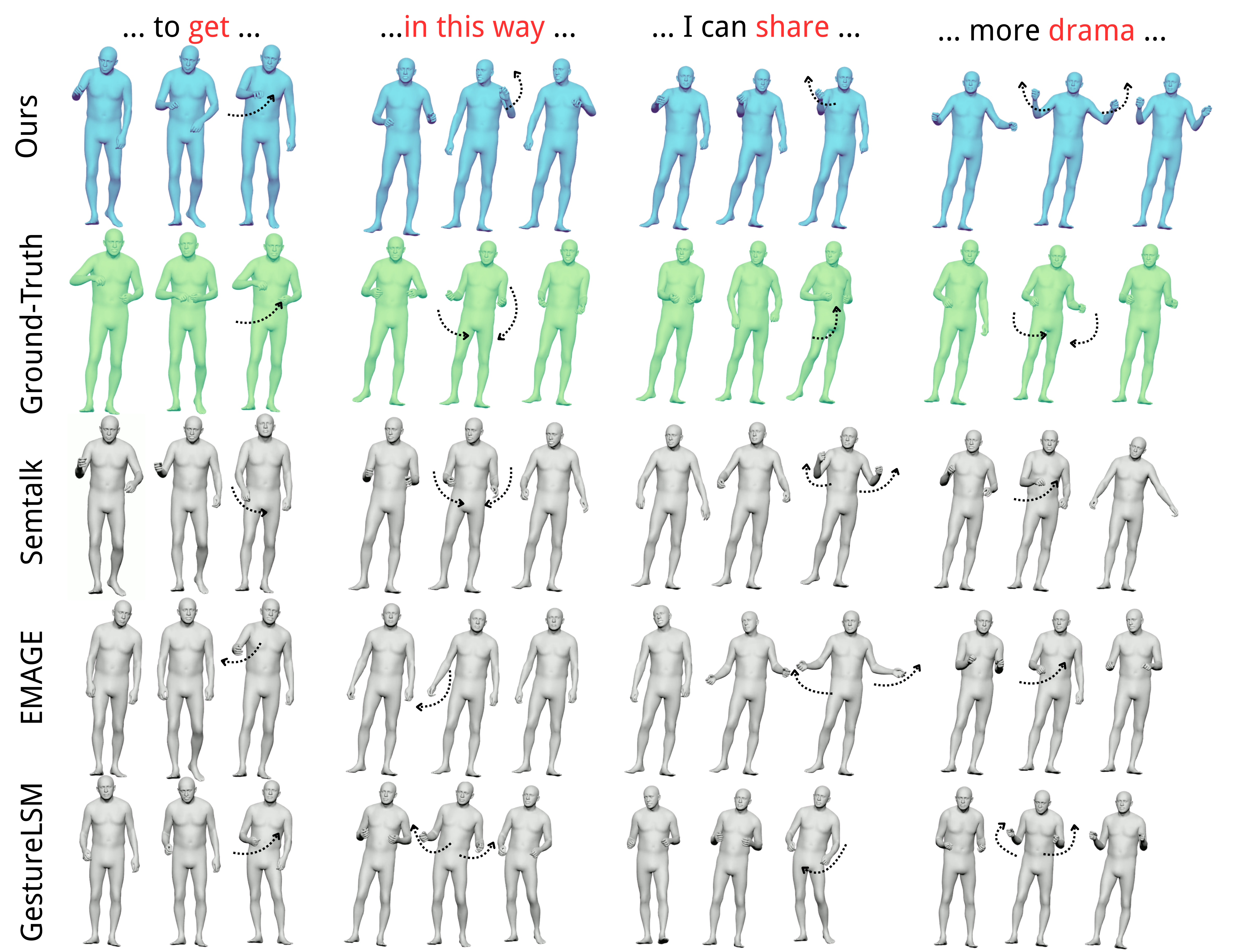
Qualitative Results
DuoGesture generates clearer, more content-aware gestures for semantic phrases such as “to get,” “I can share,” and “more drama,” while maintaining natural rhythmic consistency for beat gestures.
Demo Videos
Featured videos from the user study, with one explicit comparison against Ground Truth.